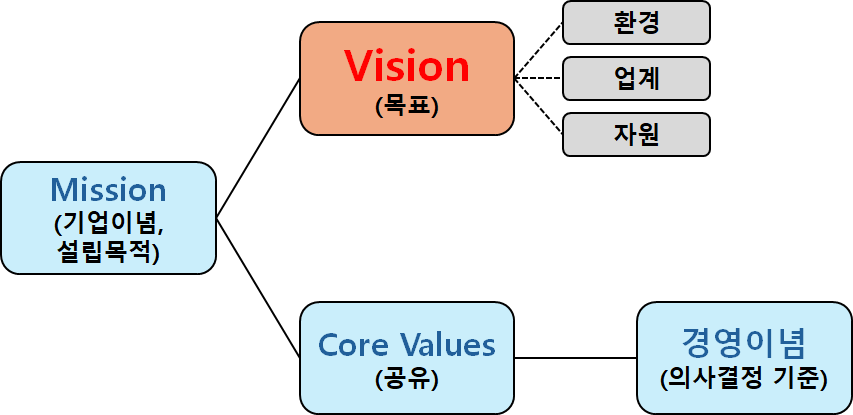
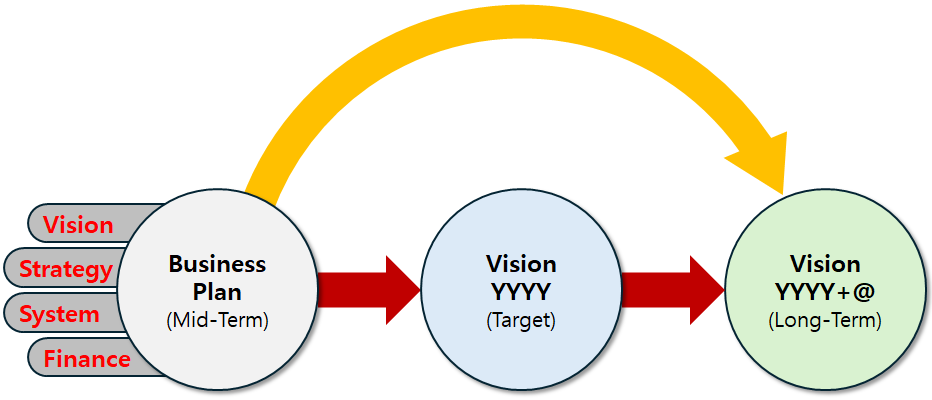
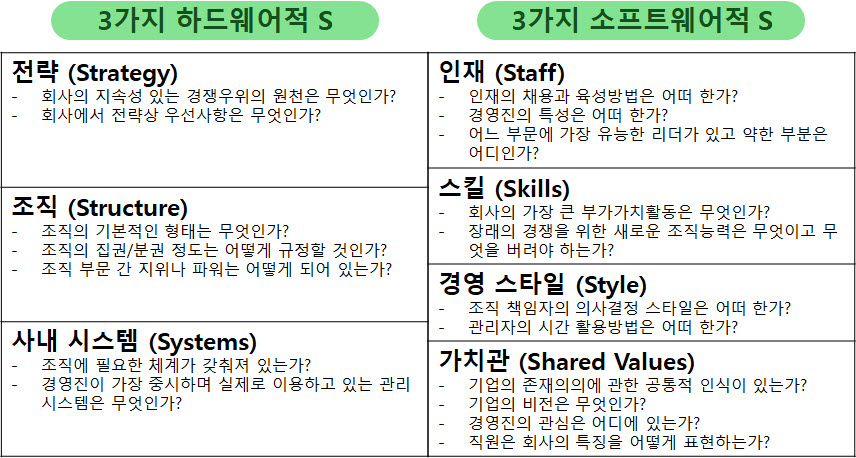
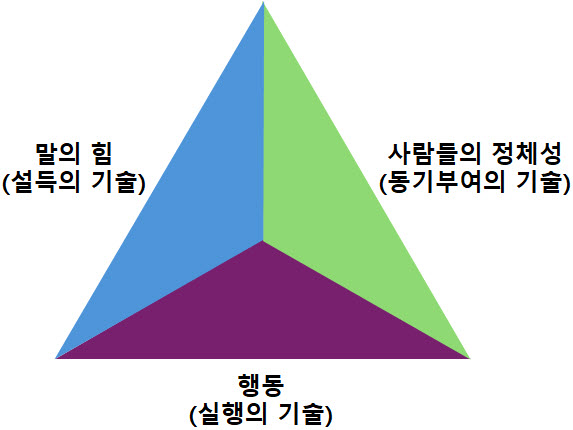
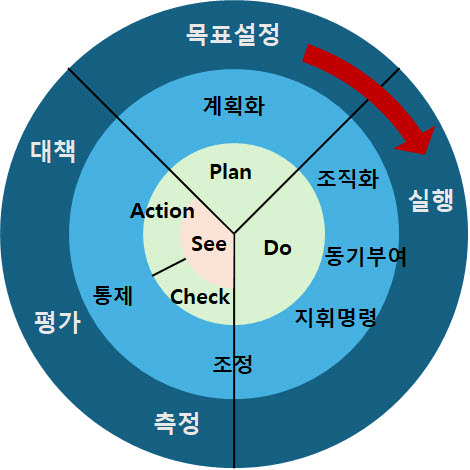
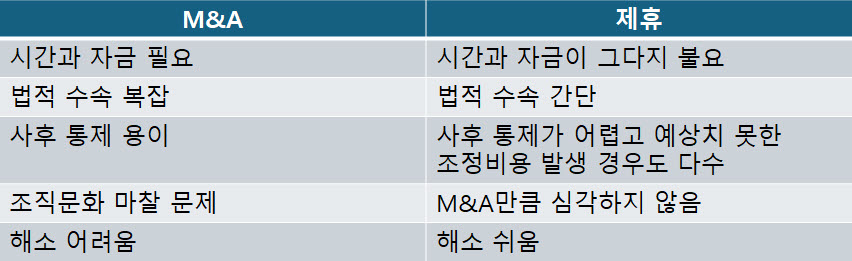
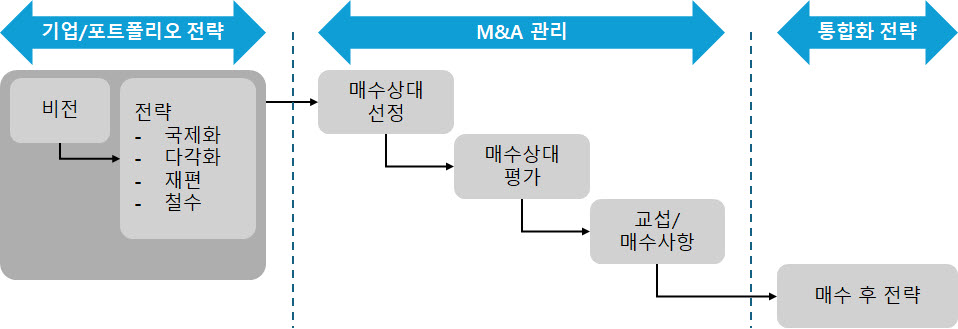
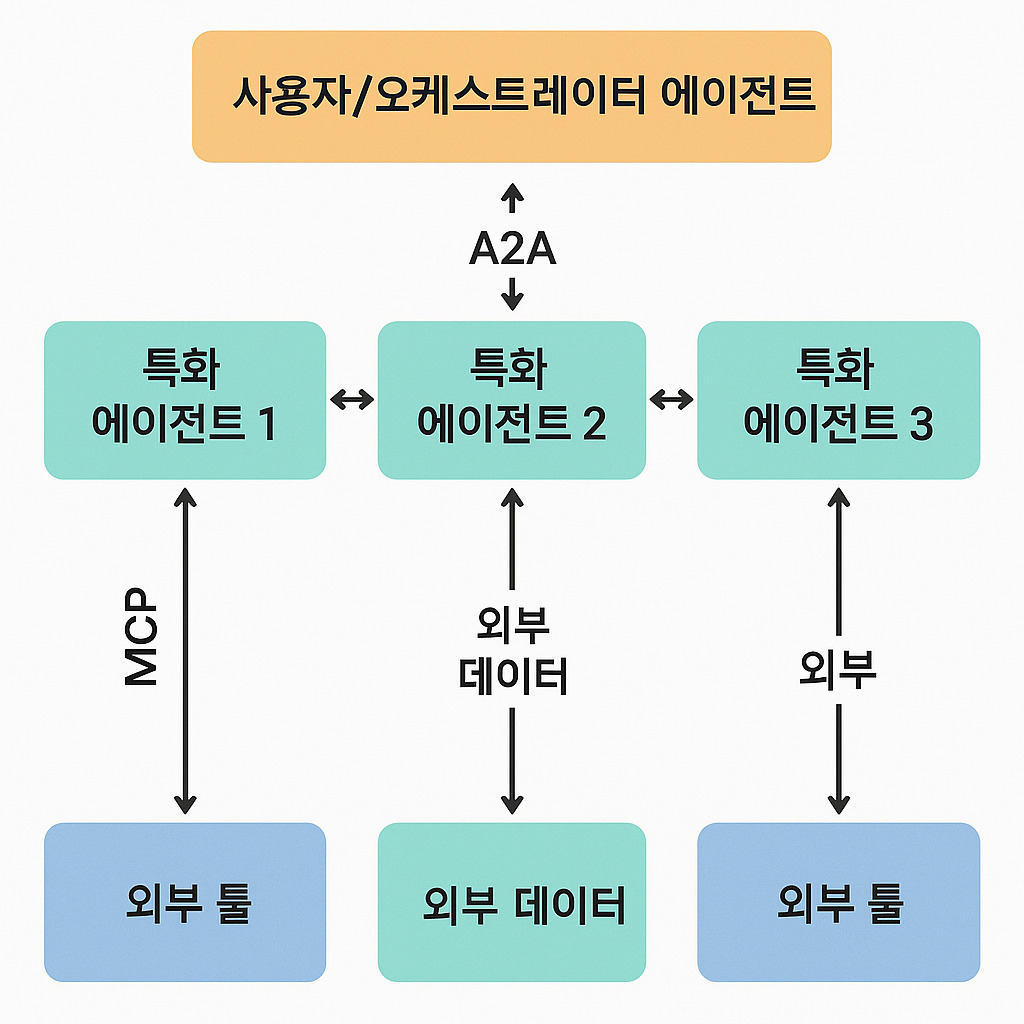
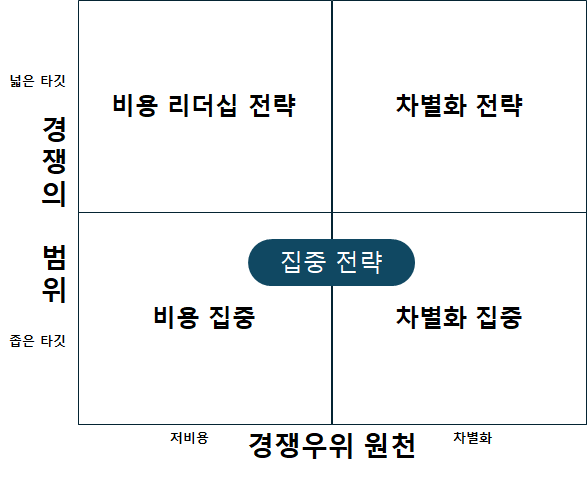
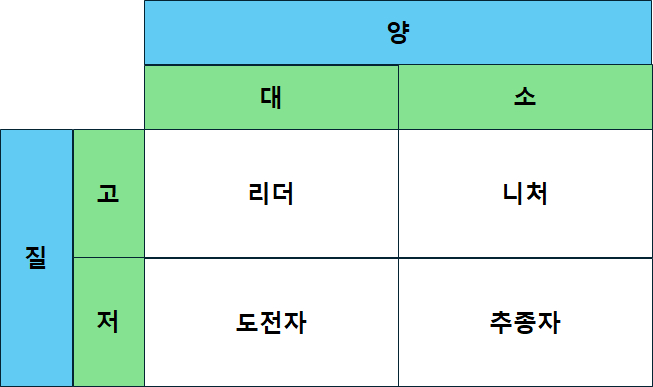
기업은 성장하면서 변해간다. 이해관계자도 바뀌고 사업의 내용이나 규모도 달라진다. 기업을 둘러싼 환경 역시 항상 변하고 있다. 이렇듯 기업이 변해감에 따라 사업을 시작할 때 만든 비전은 조금씩 새로운 기업상에 걸맞지 않게 되고 창업기를 거쳐 전환기를 맞이한 기업은 비전도 전환기에 어울리는 것으로 만들지 않으면 안 된다. 기업의 성장 단계별 비전을 고민해야 한다.
1. 창업기의 특징
기업의 성장 단계를 구분하는 방법은 많으나 어떠한 이해관계자가 경영에 관여하는지가 매우 중요하다. 창업기에는 창업자가 사업을 시작하려고 마음먹고 주변 사람들에게 같이 하자고 권유하거나 투자를 희망하기도 하면서 사업을 시작하는 단계이다. 이때의 이해관계자는 창업자와 가까운 사람들뿐이다. 이는 전혀 이상하지 않다. 자금도 없고 설비도 없다. 사람도 신용도 없고 오로지 창업자의 포부와 열정만 있을 뿐이다. 이렇듯 인재와 자금이 부족하지만 해야 할 일들은 산더미처럼 쌓여있다. 창업자는 사원처럼 현장을 훑으며 물불을 가리지 않고 일해야 할 시기이기도 하다. 창업자가 쉴 새 없이 일할 각오가 되어 있지 않으면 사업을 절대 제대로 추진할 수 없다.
2. 창업기의 비전
이러한 시기에 비전은 어떻게 세워야 하나? 앞서 언급한 여러 요건을 만족시키려 노력은 하지만 창업기에는 특히 중요한 것들이 있다.
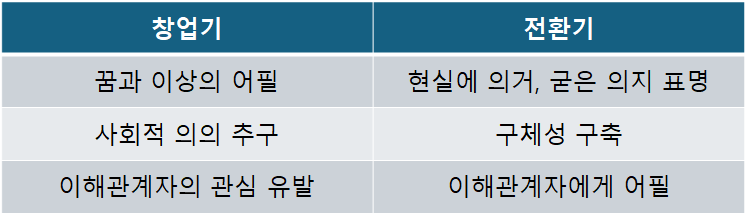
✔️ 꿈과 이상을 공유한다: 경영자원이 부족하지만 할 일은 많은 이 시기에는 이해관계자의 의욕을 돋우고 힘을 합쳐 나갈 수 있는 꿈과 이상이 필요하다. 이는 사업 시작의 계기가 되는 경우가 많으며 자연스럽게 비전으로 표현할 수 있다. 알기 쉽게! 표현하지 않으면 아무도 모른다.
✔️ 사회적 의의를 강조한다: 사업의 사회적 의의를 강조하는 일은 사내만 아니라 사외 이해관계자에게 호소할 수 있는 좋은 효과가 있다. 아무리 작은 기업이라도 사회의 일원이기 때문에 사람들이 사회적 공헌에 호감을 갖는 것은 당연하다. 의미를 살펴보자.
✔️ 사업영역을 명확히 정의한다: 어떤 사업을 어떻게 전개할지를 명확히 하면 구체적인 경영전략을 세울 수 있고 다른 회사와 차별화도 둘 수 있다. 사업영역을 간결하고 명확하게 정의할 수 없다면 창업자 본인이 사업의 방향성에 대해 인식이 명확하지 않다는 의미이다. 이때는 원점으로 돌아가 어떤 사업을 하고 싶은지 다시 한 번 차분히 생각해 보고 모든 사람이 알 수 있는 말로 표현하는 작업을 해야 한다. 방향이 정해지지 않은 채 무턱대고 시작하면 한정된 경영자원을 유효하게 활용하지 못하고 따라서 성공은 요원한 일이 된다.
✔️ 이해관계자들이 매력을 느끼도록 한다: 사업 성공이 이해관계자의 활약에 크게 의존하고 있는 이상 이해관계자가 매력을 느끼는 내용을 비전에 포함하면 그들을 좀 더 적극적으로 끌어들일 수 있다. 기업의 가치사슬에 따라 중요한 이해관계자는 시시각각 변해 간다. 단순히 여러 사람을 끌어들이는 것이 아니라 사업의 성공에 꼭 필요한 이해관계자가 누군지를 파악해 그들에게 어필하는 비전을 만드는 일은 정말로 중요하다.
3. 전환기의 특징
📌 창업기를 겪지 않은 사람들이 직원이나 책임자로 참여하고 있다.
📌 전문화된 조직이 각각의 담당업무을 수행하고 창업자 자신이 모든 것에 관여하는 일은 점점 없어진다.
📌 자금 융통이나 매출 확보로 분주해지는 일은 줄어들고 사업 확장이나 장기 계획의 책정 등에 창업자의 관심이 쏠리게 된다.
📌 거래처나 고객 등 외부 이해관계자가 늘어난다.
창업기에서 전환기에 들어서면 보통은 위와 같은 특징을 가지는데 창업기에 만든 비전도 재조명할 필요가 있다. 그 이유는?
✔️ 이해관계자의 증가: 비전을 수정하지 않으면 안 되는 이유는 이해관계자의 변화 때문이다. 일반적으로 기업이 전환기를 맞이할 무렵은 당초 계획한 사업 성공에 가까워지고 있는 시기이다. 그래서 더 큰 성장을 위해 새로운 사업영역을 찾아내야 하며 조직 형태나 비즈니스 시스템도 창업기와는 달라진다. 보다 많은 인재와 이해관계자의 참여도 필요하다. 창업기를 겪지 않은 직원의 증가는 서로를 이해해 주던 깊이가 달라지고 문화도 바뀐다. 새로 융자를 의뢰하거나 신제품을 개발할 일이 많아진다. 비교적 소수를 상대로 하던 창업기의 비전은 새로 증가한 다수의 이해관계자에게도 통용될 비전으로 바꿔 갈 필요가 있다.
✔️ 사업의 확대, 변화: 사업 자체가 창업 시와는 비교되지 않을 만큼 확대가 된다. 규모가 점점 커져 처음에 설정한 목표에 근접하게 되는 경우도 많다. 하지만 사업이나 조직은 경영자의 비전이나 목표보다 크게는 성장하지 못한다. 따라서 한 단계 더 높은 비전이나 목표를 설정하지 않으면 성장 속도는 떨어진다. 또한 창업 당시 사업 아이디어와 실제 사업 내용이 다른 경우도 많다. 이때 현실의 상황이 비전과 상이하다면 조직의 힘은 분산되어 버린다.
✔️ 환경의 변화: 경쟁사가 늘어났다든지 환율이나 원재료비, 인건비 등이 변하거나 정부의 규제나 시책 등이 변하는 상황에서 원래 계획한 대로의 비전 수행에 지장을 초래하는 일은 비일비재하다.
4. 전환기의 비전
그렇다면 빠르고 다양한 변화 속에서 경영자는 비전을 어떻게 발전시켜야 할까?
✔️ 보다 현실성 있는 비전을 제시한다: 창업기보다 현실에 적합한 비전으로 발전시켜야 한다. 막상 사업을 시작하다 보면 창업기에 예상하지 못한 일들이 자주 발생하고 창업 전에 그린 비전과 실제 사업 사이에 괴리가 생기기 마련이다. 사업의 종류에 따라 다르겠지만 사업을 하다 보면 비전을 달성할 수 있을지 달성할 수 있다면 어느 정도의 기간이 걸리지 등이 조금씩 눈에 보이기 시작한다. 이때 현실에 따라 장래 어떤 방향으로 나아가면 좋을지 검토해야 한다. 이 과정을 거치지 않으면 비전은 조금씩 현실에서 벗어나 전혀 실현 불가능한 것이 되어 버린다.
✔️ 구체적인 비전을 제시한다: 구체성! 전환기에는 이해관계자의 수가 많아져 각 이해관계자의 관여 정도도 다양해진다. 그런 이해관계자의 이해를 구하기 위해서는 좀 더 알기 쉽고 구체적인 비전이 필요하다. 창업기부터 서로의 마음을 잘 아는 이해관계자라면 몰라도 새로 참여하는 이해관계자라면 비전을 이해하지 못할 수 있다.
✔️ 이해관계자들을 끌어들일 수 있는 매력을 부여한다: 창업기에도 적용되지만 전환기의 비전은 좀 더 사람의 마음을 끄는 매력이 있어야 한다. 전환기에는 보다 많은 직원이나 고객, 투자가, 거래처 등이 필요해진다. 그들을 끌어들이기 위해서는 현실과 괴리되지 않는 정도의 꿈을 갖게 하고 장래에는 이렇게 된다는 희망을 부여할 필요가 있다. 사업의 독자성이나 창의성을 강조하는 것도 좋은 방법이다.
✔️ 창업기의 열정을 유지한다: 비전을 보다 현실적이고 구체적으로 발전시키고 유지하는 것을 받쳐주는 것은 창업 당시의 열정이다. 하지만 열정이 사라지고 단순히 돈벌이에만 관심이 쏠려버리면 비전도 의미가 없다. 기업의 매력은 떨어지고 비전도 바뀐다. 창업기의 열정을 지지하고 사업을 지원해 온 이해관계자를 떠나가 할 수도 있다. 그런데 이런 일은 너무도 주변에서 쉽게 볼 수 있다. 경영자는 항시 낮은 자세로 깨어 있어야 한다.
5. 진화된 비전을 공유하는 방법
비전의 공유는 창업기와 전환기가 다르다. 전환기에는 조직체계가 양적, 질적, 기능적으로 변화한다. 그러면서 최고경영자의 비전이 직원에게 직접 전달될 기회도 줄어든다. 이에 비전의 침투 방법을 달리 수정할 필요가 있다. 우선 최고경영자 자신이 비전을 만들고 이해시키는 데 할애하는 시간을 늘려야 한다. 핑계는 없다. 전환기에 들어 얻은 시간을 쏟아부어야 한다. 그리고 그 결과를 조직 규모에 따라 경영진이나 책임자들에게 역할을 맡기지 않을 수 없는 경우도 생겨나는데 이때는 최고경영자가 직접 비전을 전하는 것이 아니기 때문에 신중하게 방법을 고민해야 한다. 다양한 매체로 노출을 시키되 일관됨을 잃어서는 안 된다. 사람이나 방법에 따라 다른 메시지가 전달되면 안 된다. 원칙을 정하고 단계를 밟아 하나씩 넓혀나가야 한다.