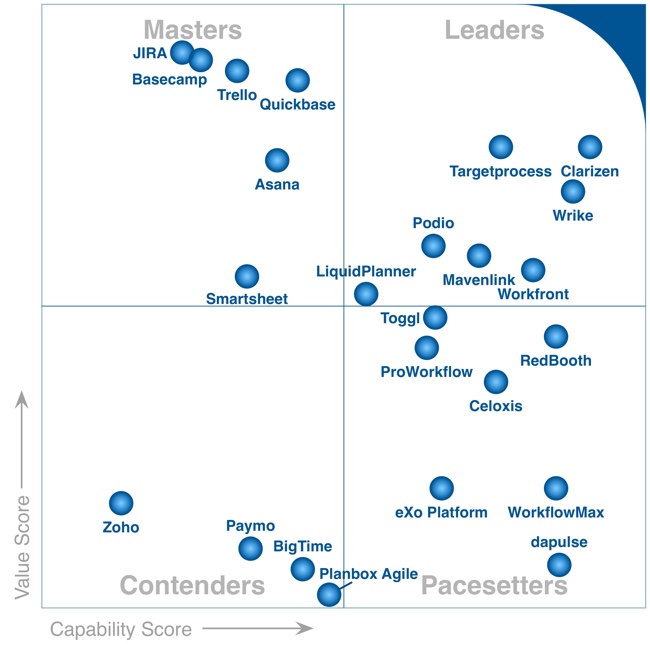
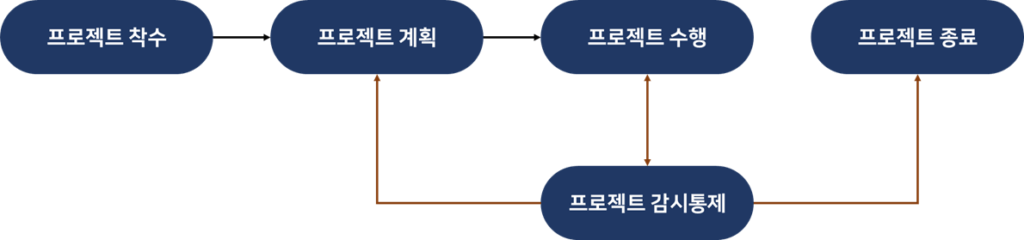
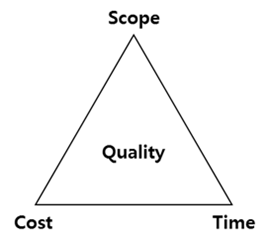
일정 관리
일정 관리는 프로젝트가 납기 내 완료될 수 있도록 보증한다. 범위관리가 무엇에 관한 것이라면 일정 관리는 언제 어떻기에 관한 것이다. 그렇다면 누구나 다 아는 일정은 그 일정일까? 프로젝트에서 일정은 다양한 의미를 내포하는데 역할로 본다면 다음과 같다.
✔️ 프로젝트의 시작과 종료 시점, 상호관계 및 마일스톤의 설정
✔️ 프로젝트 외부에서 발생하는 활동과의 조율
✔️ 프로젝트 내부의 활동 간 연관관계 설정
✔️ 수행 기간 동안 활동별 자원할당과 진행
✔️ 주요 자원 요소들 및 장애 파악
✔️ 위험 요소 파악
그러면 일정도 기준이 있을까? 있다. 일정을 작성할 때는 수행 기간과 우선순위를 따진다. 여기엔 시작 일자와 완료 일자를 기준으로 잡는 방법 두 가지가 있다.
✔️ 시작 일자 기준: 프로젝트 시작을 명시하고 활동 기간과 연관관계에 따라 종료 일자를 도출
✔️ 완료 일자 기준: 프로젝트 종료를 명시하고 활동 기간과 연관관계에 따라 시작 일자를 도출
이렇듯 프로젝트 일정은 복잡해 보일 수 있으나 정해진 프로세스가 있으며 업무 범위를 명확히 하여 프로젝트를 수립하고 통제함을 기본으로 한다. 이를 통해 범위와 원가를 잡을 수 있는데 그 구성엔 활동을 정의하고 순서를 배열하며 각각 자원과 기간을 산정하여 일정을 작성하는 흐름이다.
Critical Path
Critical Path(주요공정)는 임계경로 분석법(CPM:Critical Path Method)으로 불리는 프로젝트 관리계획 및 통제 기법으로 많이 사용된다. 이는 일련의 프로젝트 활동 일정을 짜기 위한 수학적인 알고리즘으로 시작부터 끝까지 프로젝트를 완수하는 데 드는 시간을 측정하고 가장 긴 의존 활동을 식별하여 결정한다. 이 방법은 1956년부터 1958년까지 미국 듀퐁(Dupont)사가 건설계획을 추진하면서 개발하였고 이 시기 즈음하여 미국 GM과 해군이 PERT(Program Evaluation and Review Technique)라는 것을 만들었다. 이것들은 모든 형태의 프로젝트, 예를 들어 건축, 소프트웨어 개발, 제품 개발, 각종 공학 및 연구 프로젝트에 널리 쓰이고 있다.
그래서 흔히 들어본 PERT/CPM이 바로 이것이다. PERT는 계획단계에서 공사 기간 단축이 요구되는 때에 비관치, 낙관치, 실제 가능치를 고려하여 공수를 산정한다. CPM은 최소의 비용 증가로 공사 기간을 단축하려 하는 방법으로 각 작업의 시간당 비용증가율을 비교하여 산정하는데 PERT는 활동 수행 기간 추정에 확률 개념을 반영한다는 측면에서 CPM과 구분된다.
다시 말해 CPM은 프로젝트 계획, 리소스 할당 및 작업 일정 계획에 대한 통찰력을 제공하며 이를 사용해야 할 이유는 몇 가지가 있다.
🚩 향후 계획 개선: 현재 진행상태와 기대치를 비교, 현재 프로젝트의 데이터를 추후 프로젝트 계획에 반영한다.
🚩 효과적 자원관리: PM이 작업 우선순위를 정하는 데 도움이 되고 자원을 적재적소에 배치하는 법을 지원한다.
🚩 업무 지연 방지: 네트워크 다이어그램을 이용하여 프로젝트 종속성을 계획하여 일정을 계획한다.
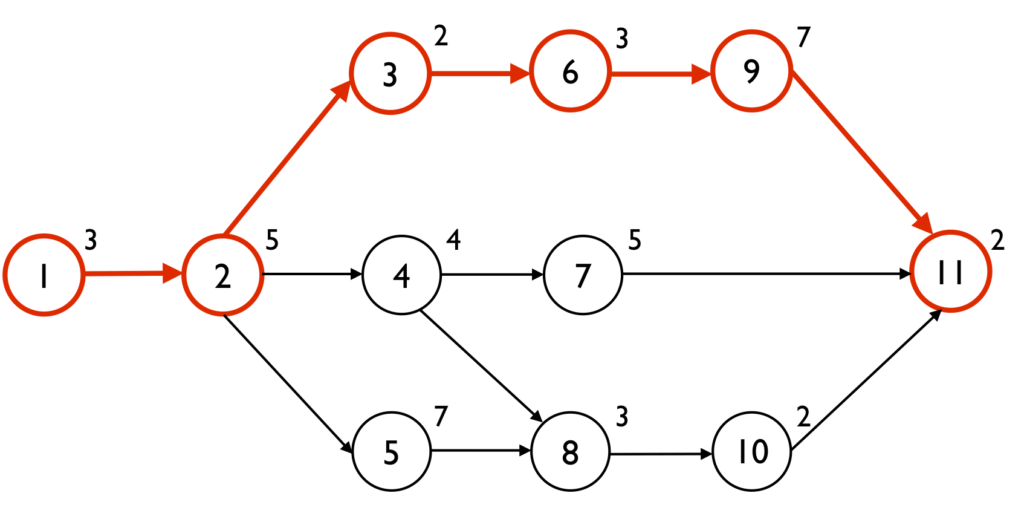
< Critical Path 예 >
Critical Path는 종속성이 중요한데 이는 활동 중 시작일과 종료일 사이의 관계를 말하여 활동 간 논리적 관계를 이야기한다. 이때 지연과 선행을 염두에 두고 작업을 하여 WBS 활동의 전후 관계를 살피고 네트워크 다이어그램을 작성한 뒤 연관관계를 파악하여 프로젝트 종료일과 여유시간을 찾아 공정을 마련한다.
✔️ 지연(lag)은 작업 종료 후 후행 작업을 기다리는 시간이다
✔️ 선행(lead)은 작업 종료 이전 후행 작업이 시작되어 두 작업이 중첩된 시간을 말한다.
✔️ Critical Path는 여유 시간이 없는 일련의 업무와 작업으로 프로젝트 납기일에 영향을 끼치는 활동들의 집합이다.
공수 산정
산정은 프로젝트팀원에 의해 이뤄져야 하며 실제 업무수행을 통해 시행착오를 거쳐야지만 체득할 수 있는 기술이다. 여기엔 여러 가지 방법들이 있는 대표적으로는 이전 유사한 프로젝트의 경험을 바탕으로 산정하거나 다수의 프로젝트 수행으로 구축된 DB나 방법론을 쓰기도 하고 PERT나 Function Point도 사용한다. 우리나라의 경우에는 한국소프트웨어산업협회에서 소프트웨어 사업 추진 시 SW 개발비 등에 대한 적정 대가를 산정하기 위한 기준으로서 “SW 사업 대가 산정 가이드”를 공표하니 이 자료를 자세히 참고해 보는 것도 업무 진행에 많은 도움을 받을 수 있다.
일정 관리 도구
도구들은 너무도 많아 일일이 나열하기도 뭐하다. 하지만 가장 기본이 되는 두 가지 정도만 챙겨도 도구 사용엔 별다른 문제가 없을 것이다.
🚩마일스톤 : 목표를 달성하기 위해 중간중간 발생하는 주요한 이벤트로 프로젝트 기간 중 주요 달성 및 완료의 표식이며 주요 산출물의 달성일을 말한다. 마일스톤은 할당된 기간이 없고 일정표상에 비어있는 다이아몬드(◇)로 기술하며 프로젝트 상 중요한 일자에 stakeholder와의 의사소통에 중요하게 쓰인다.
🚩간트차트 : 일명 Bar 차트로 진척 보고나 통제용으로 주로 쓰인다. 전체 프로젝트의 시작과 종료 기간을 한눈에 볼 수 있고 모든 활동이 기술되어 있어서 프로젝트 내 진척도에 대한 확인 및 의사소통에 주로 사용된다. 작성은 간단하게는 엑셀과 함께 전문화된 많은 툴이 있어 프로젝트 맞는 것을 골라 적극적으로 사용하는 것이 좋다.
※ 사용하실 겁니까?
도구가 없었을 땐 손으로 그렸지만, 지금은 그럴 필요가 전혀 없다. 다만 도입보다도 중요한 것은 경영층과 관리자층의 의지이다. 막상 도입은 했는데 쳐다보지도 않는다면 아래에선 죽어라 하고 헛일만 하는 것일 뿐. 이럴 바에 개발에라도 더 신경 쓰길 원하는 것이 그들의 마음이다. 현실과 괴리되어 흘러가는 프로젝트는 죽은 것이나 다름없다. 괜스레 사람들 빠져나간다고 뭐라 말고 나부터 돌아보자.