A2A와 MCP: AI 에이전트 시스템의 미래를 이끌 핵심
최근 하루가 멀다하고 발전하고 있는 인공지능(AI) 에이전트와 대규모 언어 모델(LLM)은 소프트웨어 개발의 새로운 장을 계속 써내려 가고 있다. 이러한 변화의 선단에는 A2A(Agent-to-Agent) 프로토콜과 MCP(Model Context Protocol)라는 두 가지 핵심 기술이 포진해 있다. 이들은 서로 다른 지향점을 가지고 있지만 함께 적용될 때 다중 에이전트 시스템에서 엄청나게 큰 시너지를 발휘할 수 있으며 AI 에이전트가 자율적인 실행과 협업을 구현하는 근간이 된다.
1. A2A와 MCP의 관계 및 역할: 상호 보완적인 AI 통신 프로토콜
요즘 가장 핫한 A2A와 MCP는 경쟁 관계가 아닌 수평-수직 보완 관계에 있다고 볼 수 있다. 두 프로토콜 모두 JSON-RPC 2.0 및 HTTP+SSE(Server-Sent Events)를 전송 방식으로 사용하고 있으며 주요한 특징은 다음과 같다.
-
A2A (Agent-to-Agent)
- 정의/목적: A2A는 서로 다른 AI 에이전트 간의 협업 및 작업 분배를 표준화하는 프로토콜로서 AI 에이전트 간의 직접적인 통신과 협력을 가능하게 하는, Google이 2025년 4월에 도입한 개방형 표준이다.
- 핵심 구조 및 기능: Agent Card, Task, Artifact, SSE 스트림으로 구성되며, 에이전트들이 서로를 발견하고, 작업을 위임하며, 실시간 업데이트를 스트리밍하여 복잡한 프로세스를 조율할 수 있도록 지원한다. 이는 느슨한 결합, 모달 혼합, 장기 작업에 최대의 강점을 가진다.
- 한계: A2A 자체로는 외부 리소스 직접 호출 기능이 없다.
- 역할: 에이전트 조직도를 설계하고 에이전트 간 통신과 협력, 정보 교환 및 작업 위임을 담당하는 ‘가로 축’ 또는 ‘팀 코디네이터’ 역할을 한다.
-
MCP (Model Context Protocol)
- 정의/목적: MCP는 각 에이전트가 외부 도구 및 데이터를 안전하게 호출하는 방식을 표준화하는 프로토콜로서 Anthropic이 2024년 11월에 발표한 개방형 표준이며 OpenAI, Google DeepMind 등 주요 AI 기업들이 다수 채택하고 있다.
- 핵심 구조 및 기능: Server, Client, Tool, JSON Schema I/O로 구성되며, AI 모델, 특히 LLM이 외부 데이터 소스와 도구에 연결되는 방식을 표준화하여 에이전트가 작업을 수행하는 데 필요한 컨텍스트와 기능을 제공한다. 이는 타입 안전성, 표준 함수 호출, 컨텍스트 공유에 강점이 있으며 AI 모델이 외부 시스템에 직접 연결되어 정보를 가져오거나 기능을 실행할 수 있도록 지원한다.
- 한계: MCP에는 다중 에이전트 조정 로직이 없다.
- 역할: 각 노드(에이전트)에 필요한 외부 능력을 연결하고 에이전트와 외부 Tool/DB 연결, 맥락 및 기능 제공을 담당하는 ‘세로 축’ 또는 ‘도구 상자’이자 ‘컨텍스트 제공자’ 역할로서 종종 AI 시스템의 ‘사서이자 보안 요원’으로 비유되기도 한다.
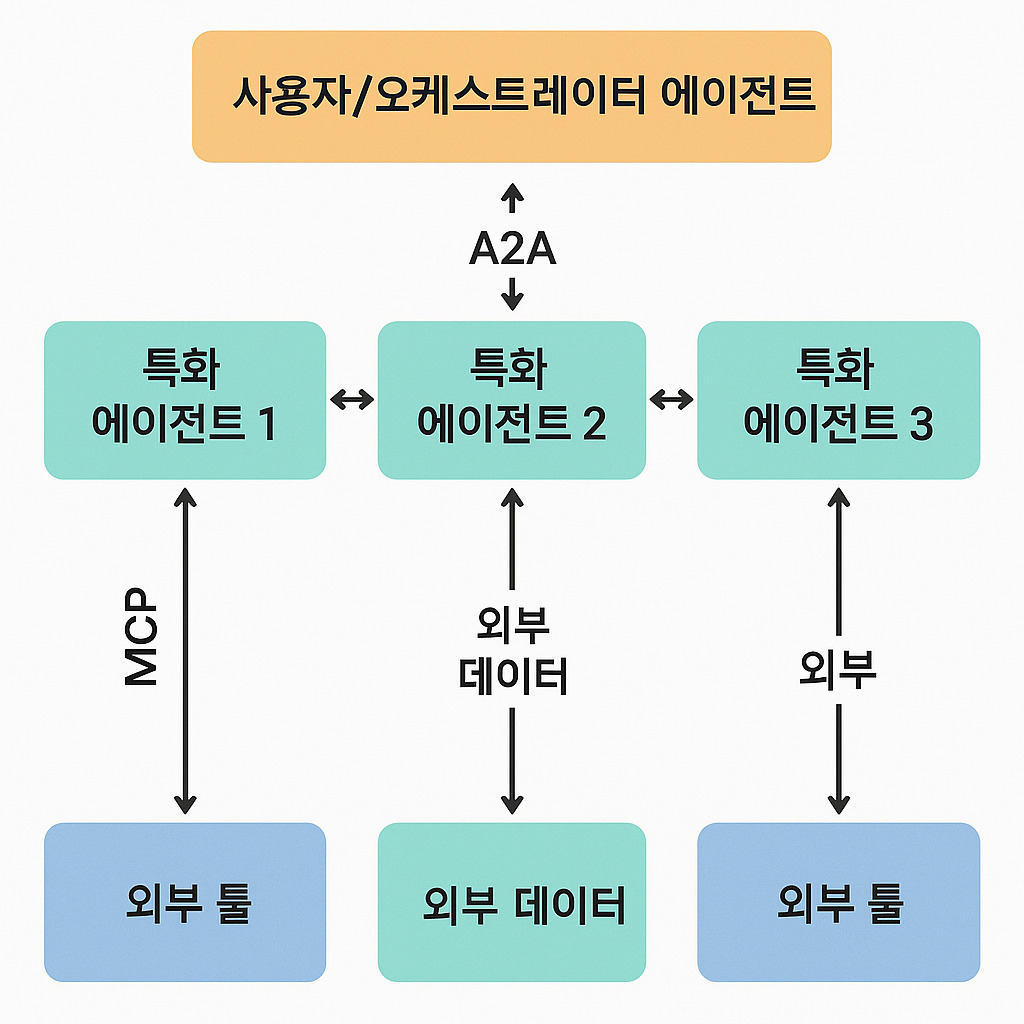
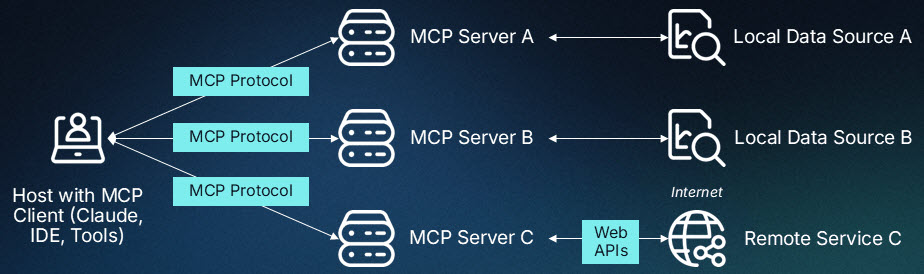
< A2A-MCP 협업 아키텍처 >
2. 시너지를 위한 협업 방법: 다중 에이전트 시스템의 강화
A2A와 MCP를 함께 사용하면 다중 에이전트 시스템(여러 개의 지능형 에이전트가 상호 작용하여 협력 또는 경쟁을 통해 복잡한 문제를 해결하거나 문제를 달성하는 시스템)에서 역할 분담은 A2A로, 능력 확장은 MCP로 분리되어 설계, 보안, 스케일이 쉬워진다. 이들은 ‘수직 통합(MCP)과 수평 통합(A2A)의 결합’을 통해 다수의 에이전트, LLM, 그리고 다양한 컨텍스트 소스가 모두 협력해야 하는 시스템 구축의 핵심 과제를 해결할 수 있는 방안을 제시한다.
- 시너지 구조 설계 방법:
- 오케스트레이터 에이전트: 사용자 요청을 수신하여 하위 작업으로 분해하고 A2A Task로 전송한다. 필요 시 Agent Card를 조회, 적합한 전문 에이전트를 선택한다.
- 전문 에이전트: 수신된 Task를 처리하는 중 외부 검색, RAG(Retrieval-Augmented Generation: 검색 증강 생성), DB 쿼리 등 도구 호출이 필요하면 자체 MCP Client로 연결한다. 도구 결과를 Artifact로 래핑하여 A2A 답신을 보낸다.
- MCP 서버: GitHub, Slack, Postgres, 사내 ERP 등 각종 리소스를 JSON Schema로 노출하고 MCP가 타입 검증을 수행하여 에이전트-도구 간 계약을 유지한다.
- 협업 최적화 팁:
- Agent Card 설계: skills 키에 MCP tool capability 태그를 작성, 오케스트레이터가 도구 사용 가능 여부를 빠르게 판단할 수 있도록 한다.
- Task chunking: 장기 작업은 A2A sendSubscribe를 통해 진행 상황 스트림을 받아 UX 체감을 개선할 수 있다.
- Schema version 관리: MCP Tool JSON Schema에 version 필드를 포함하여 에이전트가 호환성 체크 후 호출하도록 한다.
- Fallback 전략: MCP 서버 장애 시 동일 Tool API를 노출하는 대체 서버를 Agent Card에 다중 등록하여 자동 Failover를 구현할 수 있다.
- 보안 및 감사: A2A는 에이전트 간 OAuth 스코프를 분리하고 MCP는 데이터 소스별 API Key를 분리하여 최소 권한 원칙을 따른다. 또한 Task/Artifact 로그를 중앙에서 수집하여 추적성을 확보한다.
- 기대 효과: 전문성 분산, 보안 분할, 개발 속도 개선을 통해 모듈형, 확장 가능하며 협업적인 AI 시스템을 구축할 수 있는데 예를 들면 핸즈프리 간편결제 서비스에서 확장성과 파트너 연동 속도를 동시에 달성하는 데 중요하다.
3. 개발자 입장에서의 구현 방법
A2A와 MCP는 모두 HTTP, JSON-RPC, SSE 등 널리 채택된 웹 표준을 기반으로 구축되었으며 모듈형 설계 철학을 통해 구성 요소를 독립적으로 개발, 배포, 업데이트할 수 있다. 또한 엔터프라이즈급 보안이 기본적으로 내장되어 있다.
-
Google의 Agent Development Kit (ADK) 활용: ADK는 A2A와 MCP를 모두 지원하며, 에이전트를 구축하는 데 필요한 구성 요소, 라이브러리, 스캐폴딩을 제공한다.
- 시스템 설계 및 에이전트 구현: 필요한 에이전트와 각 에이전트의 역할을 정의, ADK를 사용해 에이전트를 구현한다.
- MCP 설정 및 통합: MCP 서버 설정 또는 기존 서버를 활용하여 데이터와 도구에 접근할 수 있도록 한다. FastMCP 라이브러리를 사용해 MCP 서버를 생성하고 @calculator_mcp.tool( )과 같은 데코레이터로 도구를 정의할 수 있다. 또 MCPToolset 클래스를 사용해 MCP 서버에 연결하고 필요한 도구를 에이전트에 추가할 수 있다.
- A2A 통신 설정: 에이전트 간 통신 채널을 구성하여 정보 교환과 조율을 가능하게 한다. Agent Card를 게시하여 메타 데이터 및 기능을 노출하고 작업을 시작하고 메시지 및 Artifact를 관리한다.
- 테스트 및 배포: 시스템이 원활히 작동하는지 테스트하고 필요에 따라 Google Cloud의 Vertex AI Agent Engine을 통해 배포한다. Azure App Service와 같은 클라우드 플랫폼도 A2A 애플리케이션 배포에 적합하다.
-
Python 예시:
|
# A2A 클라이언트: 특정 에이전트에 Task 전송 agent_card = requests.get(“https://agent.example.com/.well-known/agent.json”).json() # 진행 상황 실시간 수신 # MCP 클라이언트: 외부 DB 쿼리 |
-
- A2A 클라이언트 (Task 전송 및 진행 상황 수신): 에이전트 카드의 엔드포인트에 Task를 JSON 형식으로 전송하고 Task ID를 통해 SSE 스트림으로 실시간 진행 상황을 수신한다.
- MCP 클라이언트 (외부 DB 쿼리): mcp_req에 도구(tool)와 인자(args)를 정의하여 MCP 서버에 요청을 보내고, 결과를 mcp_resp로 받는다.
- A2A는 Task ID로 스트리밍하고 MCP는 함수 호출-결과 패턴을 따른다.
4. 다양한 산업에서의 활용
A2A와 MCP의 시너지 효과는 다양한 산업 및 실제 시나리오에서 복잡한 엔터프라이즈 워크플로우를 혁신하는 데 활용될 수 있으며 아래는 그 몇 가지 예이다.
- 전자상거래: 추천 Agent, 재고 Agent, 배송 Agent가 A2A를 통해 협의하여 맞춤 거래를 생성하면 각 Agent는 MCP를 통해 가격/재고 DB, 물류 API를 호출하여 맞춤 오퍼를 제공하고 재고 오차를 줄인다.
- 핀테크(간편결제): 결제 Agent, KYC Agent, 리스크 Agent가 A2A Task 체인으로 연결되고 결제 Agent는 MCP를 통해 POS/BLE SDK를, 리스크 Agent는 Fraud DB를 호출하여 결제 승인 시간 단축 및 사기 감소 효과를 얻는다.
- 제조: MES Agent가 품질 Agent, 부품 Agent와 A2A로 조율하고, 부품 Agent는 MCP 서버를 통해 ERP에서 BOM을 조회하여 생산 지연을 최소화한다.
- 헬스케어: 주치의 Agent가 보험 Agent, 약국 Agent에 A2A로 처방 작업을 배분하고, 각 Agent는 MCP를 통해 EHR(전자의무기록) 및 약국 재고 API를 호출하여 환자 대기 시간을 줄인다.
- 대출 신청 처리: 대출프로세서 에이전트가 MCP를 사용하여 신용 점수 API 호출, 은행 거래 내역 검색, OCR을 통한 문서 검증을 수행한다. 검증된 데이터가 확보되면 에이전트는 A2A를 사용하여 위험평가 에이전트, 규정준수 에이전트, 지출 에이전트 등과 협력하여 대출 평가 및 실행을 진행한다.
- 여행 관리 시스템: 여행관리 Agent가 오케스트레이터 역할을 하여 사용자 요청을 분석하고 작업을 환율 에이전트, 액티비티 에이전트 등 전문 에이전트에게 A2A로 위임한다. 각 전문 에이전트는 MCP를 통해 실시간 환율 API, 예산 친화적 추천 데이터를 가져와 포괄적인 여행 계획을 제공한다.
- 고객 서비스 시스템: 청구, 기술 지원 등 다양한 영역의 에이전트가 A2A로 협력하여 고객 문제를 해결하고, MCP를 통해 고객 데이터와 지식 기반에 접근한다.
- 데이터 분석 파이프라인: 데이터 정리, 특징 추출, 모델 학습 등 각 단계의 에이전트가 A2A로 데이터를 주고받고, MCP를 통해 데이터 저장소와 계산 자원에 접근하여 대규모 데이터 처리 작업을 자동화한다.
- 기업 내부 데이터 처리: 한 에이전트가 MCP를 통해 기업 내부 데이터에 접근하고, A2A를 통해 다른 에이전트에게 그 정보를 전달하거나 작업을 위임할 수 있다.
- 온보딩 워크플로우 자동화: HR, IT, 시설 관리 등 여러 부서가 관련된 복잡한 신규 직원 온보딩 프로세스를 A2A 프로토콜을 통해 각 부서 에이전트가 협력하고, 다수의 다중 에이전트 시스템이 전체 워크플로우를 조정하여 자동화한다.
A2A와 MCP는 AI 에이전트 시스템에서 서로 보완적인 역할을 수행하며, 함께 사용될 때 더욱더 강력한 시너지를 발휘하여 AI 시스템의 모듈성, 상호 운용성 및 효율성을 극대화할 수 있다. A2A는 에이전트 간의 통신과 협업을, MCP는 에이전트와 외부 데이터 및 도구 간의 연결을 담당하며 개발자들은 Google의 ADK와 같은 프레임워크를 활용하여 이 두 프로토콜을 구현할 수 있고, 이를 통해 여행 계획, 고객 서비스, 데이터 분석 등 다양한 실제 문제 해결에 기여할 수 있다. 이 두 프로토콜은 AI 시스템이 단순히 정보를 처리하는 것을 넘어, 적극적으로 상호 작용하고, 협력하며, 실제 컨텍스트를 기반으로 행동하는 ‘에이전트 웹(Agent Web)’의 출현을 촉진하고 있다. 이는 통합 복잡성을 줄이고, 운영 효율성을 향상시키며, 거버넌스를 개선하고, 혁신을 가속화하며, 미래에 대비할 수 있는 AI 투자를 이끌어 내고 있다.